
“japanese”の並び方をテキストファイルに書き出し
今回は、文字列を指定して、
その文字列の並べ替えを、すべて書き出すプログラムを作成します。
例として「japanese」という文字列を使用します。
「japanese」という文字列の並び方をすべて出力します。
プログラムコードは↓のようになります。
import itertools #itertools の読み込み
data=[] #順列の格納リスト作成
file=open('data.txt','w',encoding='utf_8')
for x in itertools.permutations(['j','a','p','a','n','e','s','e'],r=8):
a = '' #これだと重複文字列が含まれる
for i in range(len(x)): #permunation は順列の意味
a += x[i] #’ ’を含まない文字列に組み替える
data.append(a) #data に文字列を追加
data = sorted(set(sorted(data))) #setで重複する文字列を消去
print(len(data)) #順列の数を表示
for i in range(len(data)): #sortはリスト内が文字列なら辞書順に並べる
file.writelines(data[i]+'\n') #1文字ずつファイルに出力する
file.close() #ファイルを閉じる
↑を実行してみると、

このように表示されます
これは、「japanese」という、8文字の並べ替えの種類数を表示してくれます
一応確認してみますが、

答えが一致しているので、
正しく演算されていることが分かります
それに加えて、このプログラムファイルが保存されているフォルダに
「data.txt」というテキストファイルが追加されています。
この「japanese並べ替え.py」という名のプログラムファイルは
「一時的3」という名のフォルダに保存しておいたので、
「一時的3」という名の同フォルダに「data.txt」が書き出され保存されています
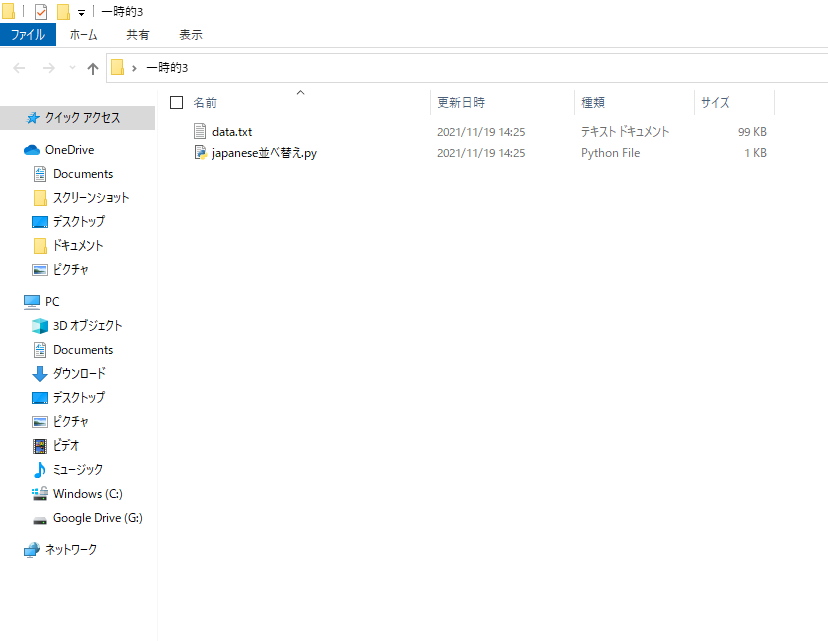
「data.txt」を開いてみると、
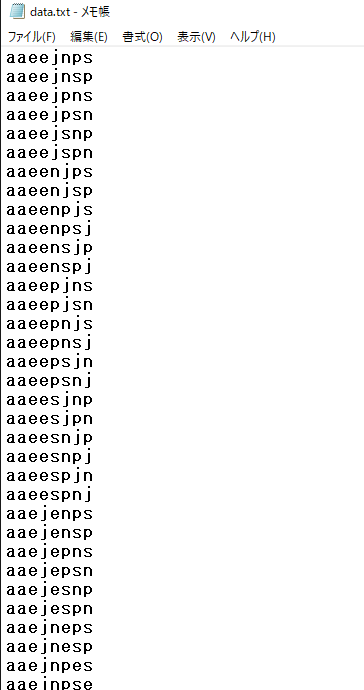
↑のように表示されています。
「j・a・p・a・n・e・s・e」という文字列を辞書順に並べてくれています。

コメント