
今回の解説では、音声データを使った機械学習プロジェクトを進めていきますが、初期のセットアップ手順は他の機械学習分野にも応用できる汎用的なものです。
wav2vec2による音声認識モデルの構築に加えて、データ準備や環境設定といった重要なステップを網羅し紹介します。本記事を通じて、音声データのみならず、広く機械学習で使える基盤づくりのスキルも習得していただけるでしょう。
今回はspyderの仮想環境で機械学習します。(仮想環境でなくても構いません)
今回使用するもの
・python
・データセット(後ほどご説明いたします)
・pytorch
本記事では、雑音をのせた音声データを使用します。機械学習の基本的な流れを分かりやすく解説し、初心者の方でも基礎を身につけやすくすることを目指しています。
この記事をみてわかること
・音声にホワイトノイズをのせる方法
・音声データを指定したHzにリサンプリングする方法
・wav2vec2を用いた転移学習の方法
pythonについては各自でご準備ください。もし仮想環境で使用したい方は↓を参考にしてください。

音声データのダウンロード
今回使用するデータのダウンロードリンク
サイト移動後、画像の個所をクリックしてファイルをダウンロードしてください。
圧縮アーカイブフォルダーでダウンロードされるので、展開までしてください。

雑音をのせてリサンプリング
雑音をのせる工程ですが、別の記事で紹介しているのでそちらをご覧ください。
こちらの記事でそのまま使用できるように構成してあるので、ご安心ください。
↓の記事を参考に「audio」にダウンロードした音声ファイルに雑音をのせてみてください。

※↑の記事を参考にされた方は
「tsuchiya_normal_with_noise」というフォルダに入っているwavファイルを
「audio」というフォルダを作成していただき、移していただくと記事の通り作業ができます。
これ以降、↑の記事で作成した「tsuchiya_normal_with_noise」を
「audio」というフォルダに移して作業していきます。
今回使用するwav2vec2モデルは、音声データのサンプリングレートが16,000Hzであることを前提に設計されています。そのため、データが16,000Hz以外の場合は正確に処理されない可能性があります。16,000Hzに変換してから使用することで、モデルの性能を最大限に引き出し、安定した認識精度を確保できます。
↓がリサンプリングするプログラムです。
「audio」に入っている音声データをサンプリングレート16000Hzにして
「resampled_audio」というファイルに保存するプログラム。

import os
import torchaudio
# 元のオーディオディレクトリとリサンプリング後の保存先ディレクトリ
original_data_dir = "audio"
resampled_data_dir = "resampled_audio"
os.makedirs(resampled_data_dir, exist_ok=True)
# 目標のサンプリングレート
target_sample_rate = 16000
# 音声ファイルを一つずつリサンプリングして保存
for filename in os.listdir(original_data_dir):
file_path = os.path.join(original_data_dir, filename).replace("\\", "/")
waveform, original_sample_rate = torchaudio.load(file_path)
# サンプリングレートが異なる場合、リサンプリングを実行
if original_sample_rate != target_sample_rate:
resampler = torchaudio.transforms.Resample(orig_freq=original_sample_rate, new_freq=target_sample_rate)
waveform = resampler(waveform)
# リサンプリング後のオーディオファイルを保存
save_path = os.path.join(resampled_data_dir, filename).replace("\\", "/")
torchaudio.save(save_path, waveform, sample_rate=target_sample_rate)
print(f"全てのファイルが{target_sample_rate} Hzにリサンプリングされ、'{resampled_data_dir}' ディレクトリに保存されました。")しかし、実行してもエラーが出ると思います。

これは、torchaudioはpytorchに依存しているため、pytorchがインストールされていないとtorchaudioをインストールできません。torchaudioはPyTorch用に設計されている音声データ処理ライブラリなので、pytorchのインストールが必要条件となっています。
ということで、PyTorchをインストールしていきます。
↓のリンクで公式サイトに移動します。
Start Locally | PyTorch

「Run this Command:」の箇所をコピーします。
spyderのコンソールにコピーしたものを張り付けて実行します。
今回の場合は、「pip3 install torch torchvision torchaudio –index-url https://download.pytorch.org/whl/cu118」となります。
こちらでならない場合は
「pip install torch torchvision torchaudio –index-url https://download.pytorch.org/whl/cu118」を試してみてください。
実行すると、

エラーがでるかもしれません。
音声ファイルの読み込みには、「soundfile」などのライブラリが必要です。
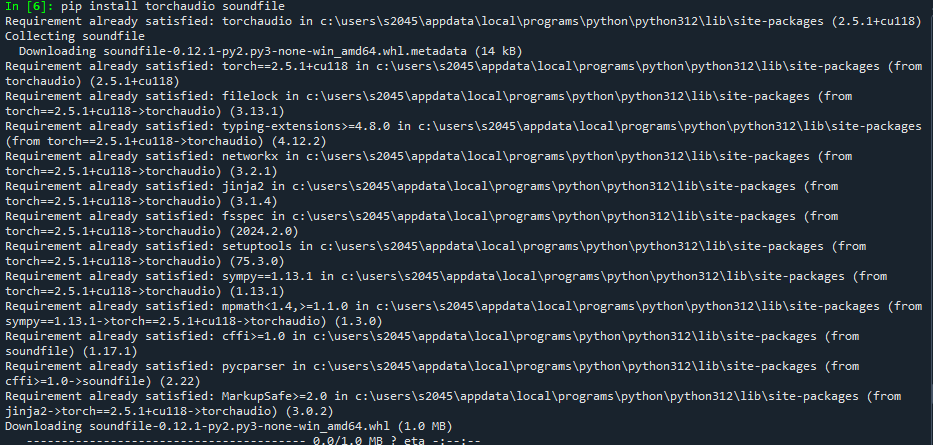
画像のように「pip install torchaudio soundfile」を入力して、
カーネルを更新すれば無事に実行されるはずです。

「resampled_audio」に出力されています。
Huggingfaceから使用モデルの選択
↓のリンクに移動してください。

「wav2vec2-large-xlsr-53-japanese」は、音声認識モデルwav2vec 2.0の一種で特に日本語の音声データに対して性能を発揮するように設計されたモデルです。今回はこのモデルを使用して機械学習したいと思います。もちろんほかの言語のモデルもあるので、ぜひ試してみてください。
プログラム実行
プログラムで使用するモジュールをインストールしてください。
「pip install transformers」
「pip install datasets」
「pip install scikit-learn」
※ここで注意なのが、pythonのversionに対応したモジュールを使用すること。
もし、不一致だとエラーが起こります。

このようなエラーがみられたら、バージョンの不一致が問題の可能性があります。
私の場合は
pythonのバージョン:3.12.6
transformersのバージョン:4.44.2
だと
うまくいきました。どうやらpythonとtransformersで一致していることが重要なようで、
pythonのバージョンが最新すぎるとモジュールの方で対応できないということが起こるようです。
「resampled_audio」と同じ階層にこちらのプログラムを
「learning.py」という名前で保存して実行してください。
※ラベルは「labels」に直接貼り付けています。
「、」「。」は削除してあります。
「learning.py」
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor, Trainer, TrainingArguments
from datasets import Dataset
import torchaudio
import torch
import os
from sklearn.model_selection import train_test_split
# モデルとプロセッサの読み込み
processor = Wav2Vec2Processor.from_pretrained("jonatasgrosman/wav2vec2-large-xlsr-53-japanese")
model = Wav2Vec2ForCTC.from_pretrained("jonatasgrosman/wav2vec2-large-xlsr-53-japanese")
# 音声ファイルとラベル
data_dir = "resampled_audio"
labels = [
"また東寺のように五大明王と呼ばれる主要な明王の中央に配されることも多い",
"ニューイングランド風は牛乳をベースとした白いクリームスープでありボストンクラムチャウダーとも呼ばれる",
"コンピュータゲームのメーカーや業界団体などに関連する人物のカテゴリ",
"サービスマネージャー導入駅のため大井町駅から遠隔管理している",
"シルバーサーファー襲撃事件までにリチャーズはチーム名と共に国際的にスーパーヒーローおよび有名人として認知されている",
"ツュレンハルト領はヴュルテンベルク領に編入された",
"時間領域と空間領域で共通する処理手法はフィルタリングによる入力信号の強化である",
"シャンチーの専業プロはチームから支払われる給料と対局費を主な収入としている",
"また禰寝氏は中山王の治める琉球王国との交易にも参加した",
"スマートフォンからフィーチャーフォンまでマルチデバイスに対応",
"軽妙洒脱なナレーションから情緒感溢れる語りまで幅広い表現力を持つ",
"構造は鋼製の単一アーチで橋脚は石積みである",
"そこへオーナーが新しいシェフとして腕利きのヒョヌクを招く",
"クィーンズアベニューアルファに所属している",
"一方で漁業と商業でリャネス港は繁栄していた",
"このニューサウスウェールズ代表チームがワラビーズの中核となって行く",
"ただしギャンブル依存症の入院治療を行っている病院はわずかである",
"他のメジャーなディストリビューションに比べセキュリティー上の問題の修正が遅い場合もある",
"ベルガートーア前のヴェディゲンウーファーパークには戦争と弾圧の犠牲者のための記念碑が建っている",
"全米パブリッシャーズ協会のベストストラテジーゲームオブザイヤーを日本人として受賞",
"痛みは点滴より鎮痛薬を静脈投与することで鎮痛を行う",
"このときに浮遊大陸プルヴァマにある中立国ビュエルバがある情報筋からバッシュ将軍の処刑と前王女アーシェの自害を発表",
"南西部ウォーレンはベイアーマンファームズとフィッツジェラルドの地区で構成される",
"このためプラズマ中のイオンや電子の持つ平均運動エネルギーを温度で表現することがある",
"その飄々とした人柄が老若男女に慕われている",
"現在ニュージャージー州ムーアズタウンに住んでいる",
"町域にあった三根山藩は長岡藩に米百俵を送ったことで有名",
"このときペリメーデーはアムピクトリュオーンに同行してテーバイに来ていたリキュムニオスに妻としてあたえられた",
"現在の滑走を目的としたスキーブーツは硬いプラスチックシェルと柔らかいインナーブーツからなる",
"防氷ブーツは表面に張られたゴム製の薄い膜でできている",
"後者の代表がウェッジウッドのジャスパーウェアである",
"キー局が発信するニュースネットワーク名を冠したタイトルのニュース番組の中ではレギュラー放送が最も多い",
"芸能プロダクションアミューズのグループ企業",
"長母音を省略してエリュシオンとも表記される",
"森永のおいしい牛乳は濃い青色に牛乳瓶をあしらったデザインのパック牛乳である",
"番組冒頭を東京ムービー製作のアニメーションで表現する点も共通していた",
"コミューンはセーヌ川とエソンヌ川の合流地点となっている",
"同時に福井ミラクルエレファンツにコーチ兼任で入団することが発表された",
"夫である小室が救急車を呼び都内病院に緊急搬送される",
"ギレスピーはマッギーを通じてイネスと知り合った",
"フォンテーヌブロー様式では寓意的な絵が漆喰のモールドに使われている",
"祭神はヴィシュヌ派の聖人スワーミーナーラーヤン",
"ハーデースがペルセポネーに恋をしたのはアプロディーテーの策略であるとされている",
"クウェーンバーンチャーンは小さなコミュニティーで農業や商業を中心に成り立っていたと考えられている",
"ヴェーザー自転車道やミューレンルートに従ったサイクリングツアーはペータースハーゲンを経由する",
"フォーミュラカーは通常オープンホイールでシングルシーターである",
"同日朝に大阪難波で出発セレモニーが開催され営業運転に充当された",
"そしてインデペンデント紙の読者投票で選ぶプレミアリーグ最優秀ゴールキーパーに選ばれた",
"プレイヤーキャラクターは宮殿を占拠した邪悪なクリーチャーに遭遇する",
"フィールドマーケティングは歴史的には一方通行のコミュニケーションツールとして考えられてきた",
"デビュー後の数年間はベビーフェイスとして本名で活動",
"学校や病院などの給食業務で栄養素を計算する上で重要な資料のひとつである",
"当時あやしいワールドに常駐していた擬古猫が空白にて発表",
"裕福なニューヨーカー達はグレーヴセンド競馬場やシープシェッドベイ競馬場などに集い海沿いの高級レストランやホテルを利用した",
"ウォリアーズミックスマーシャルアーツアカデミー所属",
"ところがエリュシクトーンはニュムペーの制止も聞かずにデーメーテールの樫を切り倒した",
"このジェシー役でステイモスはエミー賞にノミネートされたこともある",
"スウェーデン移民の両親の許にマサチューセッツ州ケンブリッジにて生まれる",
"球宴のファン投票でも人気が偶像化していた長嶋茂雄に肉薄する",
"母はピーターマリッツバーグの精神病院に入院しているときにベッシーを産む",
"ポイントガードからスモールフォワードまでこなせる総合力が高いユーティリティープレーヤーである",
"グレッグはミシシッピ州アバディーンにあるオッドフェローズ墓地に埋葬されることになった",
"大当り終了後はグラディエーターチャンスに突入する",
"この菌による病気は灰色かび病と名づけられているものが多い",
"レギュラーメンバーの顔写真をクリックした後にムービープレイヤー風に再生されるという特異な形式となっている",
"肝臓への酸素供給は肝動脈と低圧系の門脈を介して行われている",
"デッドキーはタイプライターやコンピュータのキーボードにおける特殊な装飾キーである",
"シャンシャン馬は鵜戸神宮へ参拝する新婚夫婦が乗っていた馬のこと",
"ブルーリッジ山脈の源流からリッチモンドまで多くの早瀬や淵が釣りや急流くだりを楽しませてくれる",
"ボーハンはイーストマンらギャングのスピークイージーの上がりから賄賂を取っていたとも噂された",
"ペンシルベニア州フィラデルフィアの郊外ウィンレッドのレンキナウ病院で生まれた",
"ブラッグはビューエル軍よりも劣勢だったためにこの機会を生かすことを躊躇した",
"上院議員としてバーンウェルはカリフォルニア州の連邦加入に賛成した",
"レジェンドシリーズをベースにヨーフリー機構を備えたビューカメラ",
"楽曲のセンターポジションはエーケービーフォーティーエイトの高橋みなみが務めた",
"ディオニューソスの寵愛を受けるオイネウス王と妃アルタイアーの間にカリュドーンの王女として生を受けた",
"大西洋上の巡航高度から動力なしで地上へ滑空飛行し緊急着陸に成功した",
"表現行列の指標表を分子の対称性を表す点群の指標表を用いて既約表現へ分解する",
"大洋漁業オーナーの中部謙吉の命を受けてプロ野球球団の大洋ホエールズに関わる",
"かすかに聞こえてくる1931年版の讃美歌が次第に大きくなっていく",
"モーイーデーン岩壁地域の上部はプラーサートプラウィハーン寺院遺跡へ繋がるタイ側参道に続いている",
"カーミラ星と呼ばれている惑星から宇宙船に乗って地球に侵入した宇宙人",
"ドッガーバンクはタラやニシンの漁獲量が多い重要な漁場である",
"少年時代はロシア帝国チェルニーヒウ県プルィルークィ郡トロスチャヌィーツャ村で過ごした",
"遺灰のほとんどはスウェーデン西海岸のブーヒュースレーン地方の小島にある漁村フヤルバッカ周辺の海に散骨された",
"国境を越えて列車は改良された在来線に沿ってアーヘン中央駅に向かう",
"福岡ダイエーホークスではなく長距離砲の補強を目指していた大阪近鉄バファローズからオファーを受けて入団",
"そこには百ドル札とアメリカに来いという短いメッセージだけだった",
"現在はバッハをモチーフとしたハープシコードの作曲家として記憶されている",
"戦闘服は両腕を露出し両脚がアンダースーツで覆われている",
"同母姉にスウェーデン王妃ジョゼフィーヌがいる",
"紫外線は表面エネルギーの小さいポリマーを接着する際の前処理に利用される",
"自身のページでメッセージや公開コメントを通してレビューを投稿したユーザーとコミュニケーションを取ることが可能である",
"若き日の反逆ゆえに宇宙の中央を追放されて惑星地球にやってきた主人公ベルゼバブが宇宙船カルナークのなかで孫に語る壮大な物語",
"ジャガーとは対照的にボディービルダーを髣髴とさせるマッチョな体育会系の外見が特徴",
"ペンシルベニア州ピッツバーグのアレゲーニー高校を卒業しカリフォルニア大学バークレー校に入学",
"この概念の導入によって様々なバリエーションの流体のコンピューターシミュレーションが高い精度で可能となった",
"乾ドックに入渠してオーバーホールすべきかどうかパフォーマンスがチェックされた",
"デビューウェイトはスーパーバンタム級ではなくフェザー級だった",
"アーリーは降雨の中を南のバージニア州ウィンチェスター近くのフィッシャーズヒルまで軍を退いた"
]
# ファイルパスを取得
file_paths = [os.path.join(data_dir, f).replace("\\", "/") for f in sorted(os.listdir(data_dir)) if f.endswith(".wav")]
# ファイル数とラベル数の確認
assert len(file_paths) == len(labels), "音声ファイル数とラベル数が一致しません"
# ラベル付きデータの準備
labeled_data = {"audio": file_paths, "text": labels}
labeled_dataset = Dataset.from_dict(labeled_data)
# データセットをランダムに分割(8:2)
train_indices, eval_indices = train_test_split(range(len(labeled_dataset)), test_size=0.2, random_state=42)
train_dataset = labeled_dataset.select(train_indices)
eval_dataset = labeled_dataset.select(eval_indices)
# サンプリングレートとデータ長を設定
resample_rate = 16000 # モデルが期待するサンプリングレート
max_length = resample_rate * 10 # 10秒分のデータ(16000Hz * 10秒)
# データ前処理用の関数
def prepare_labeled_dataset(batch):
audio = batch["audio"]
waveform, original_sample_rate = torchaudio.load(audio)
# サンプリングレートが異なる場合、16000 Hzにリサンプリング
if original_sample_rate != resample_rate:
resampler = torchaudio.transforms.Resample(orig_freq=original_sample_rate, new_freq=resample_rate)
waveform = resampler(waveform)
# 音声データを max_length にトランケートまたはパディング
if waveform.shape[1] > max_length:
waveform = waveform[:, :max_length] # トランケート
else:
padding = max_length - waveform.shape[1]
waveform = torch.nn.functional.pad(waveform, (0, padding)) # パディング
input_values = processor(
waveform.squeeze(),
sampling_rate=resample_rate,
return_tensors="pt",
padding="max_length",
max_length=max_length,
truncation=True
).input_values
# ラベルのトークン化とパディングの設定
with processor.as_target_processor():
labels = processor(
batch["text"],
return_tensors="pt",
padding="max_length",
max_length=80, # 最大 80 トークンに制限
truncation=True
).input_ids
# パディングされた無効なラベル部分(0)を -100 に置き換え
labels[labels == 0] = -100
return {"input_values": input_values[0], "labels": labels[0]}
# データセットの前処理を行う
train_dataset = train_dataset.map(prepare_labeled_dataset, remove_columns=["audio", "text"])
eval_dataset = eval_dataset.map(prepare_labeled_dataset, remove_columns=["audio", "text"])
# トレーニング設定
training_args = TrainingArguments(
output_dir="./wav2vec2-finetuned",
per_device_train_batch_size=4,
gradient_accumulation_steps=2,
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=1e-4,
num_train_epochs=10,
warmup_steps=10,
save_total_limit=2,
fp16=True,
remove_unused_columns=False,
gradient_checkpointing=True,
logging_steps=10,
log_level='info',
logging_dir="./logs",
report_to=["tensorboard"]
)
# トレーナーの設定
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset
)
# トレーニングの実行
trainer.train()
# モデルとプロセッサを保存
model.save_pretrained("./wav2vec2-finetuned/final_model")
processor.save_pretrained("./wav2vec2-finetuned/final_model")
確認
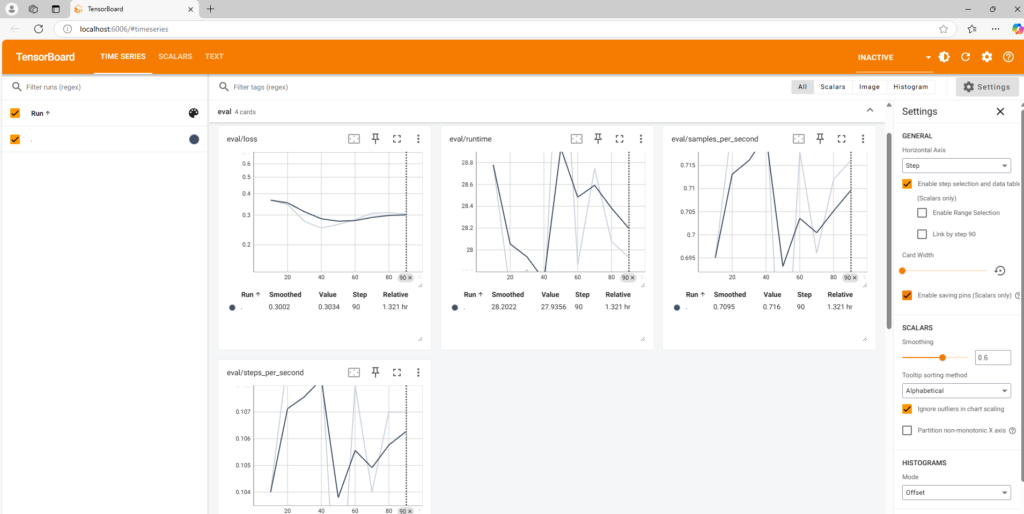
今回は「tensorboard」を使用して、loss値の推移を確認してみます。
※「tensboard」をインストールされていない方は
コマンドプロンプトで↓を入力
pip install tensorboardすると、現在のディレクトリに関係なく、
システムに登録されているPython環境にインストールされます。
仮想環境にpythonをインストールされていて、仮想環境から作業している場合は、
仮想環境を有効化してから入力してください。
コマンドプロンプトでさきほどのpythonプログラム「learning.py」
が保存されているディレクトリに移動してみてください。
プログラムを実行すると、「logs」というファイルが作成されているはずです。
そのログファイルの絶対パスをコピーして↓のコードにあてはめて、
コマンドプロンプトで実行してみてください。
tensorboard --logdir=「ログファイルが保存されているディレクトリの絶対パス」「C:\Users\username\projects\logs」
に保存されている場合
「tensorboard –logdir=C:/Users/username/projects/logs」と入力します。
入力すると、
↓のように表示されます。

http://localhost:6006/となっている箇所は
「ctrl」+「クリック」でtensorboardのサイトに飛ぶようになっています。
tensorboardの実行結果の画像
おわり
今回のプログラムは「resampled_audio」に入っている音声データをランダムな順番にして、訓練データ8:評価データ2に分ける。それを用いてwav2vec2.0で転移学習を行いました。


コメント