
音声データを用いた機械学習や音声認識の研究では、雑音が含まれる環境でのモデルの性能を評価することが重要です。特に、雑音耐性を向上させるためには、訓練データや評価データに様々な種類の雑音を加える「データ拡張」が効果的です。この記事では、Pythonを使って音声データに雑音を加える方法を紹介します。
まずは、基本的な「ホワイトノイズ」を加える方法から始め、次に、自然界の音やダウンロードした音声ファイルを利用して雑音を追加する方法まで、具体的な手順を解説します。これらの手法を活用することで、より実用的な音声認識モデルを構築する足がかりとなるでしょう。
音声処理に興味のある方や、雑音環境下での精度向上を目指している方は、ぜひこの記事を参考にしてみてください!
音声データの準備
まずは、ホワイトノイズを追加するプログラムを考えたいのですが、
その前に、ノイズをのせるメインの音声を準備しましょう。
ノイズをのせるメインの音声が準備できていない方は
こちらからご準備ください。
https://voice-statistics.github.io/
「日本声優統計学会」が配布しているwavファイルです。
高品質な音声に加えて、ラベルが準備されているので
今回はこちらを使用していきます。
「土谷麻貴様」の下にある「通常」といところクリックしてください。
「tsuchiya_normal」というフォルダのダウンロードが始まると思うので、
ダウンロード後はお好きなフォルダに保存してください。
※この記事では、「ノイズ追加」というフォルダを作成し、そこに保存します。

「ノイズ追加」に「tsuchiya_normal」が準備できたら、
ホワイトノイズをのせていきたいと思います。
wavファイルを使用する際の注意点
wavファイルを読み込む「pydub」モジュールをインストールするだけでは、
wavファイルは読み込めません。
「pydub」で内部使用する「FFmpeg」をインストールする必要があります。
また、インストール後パスを指定する必要があります。
↓のサイトで、「FFmpeg」のインストールとパス通しが丁寧に解説されていますので、
せひ参考にしてみてください。
WindowsにFFmpegをインストールして利用できるようにパスを通す | taziku / AI × クリエイティブ | 東京・名古屋
ホワイトノイズの追加
「ノイズ追加」というフォルダに
こちらのプログラム「with_whitenoise.py」という名前で保存してください。
「with_whitenoise.py」
※実行前に必要なモジュールをインストールしてください。
import os
import random
import numpy as np
import soundfile as sf
# 入力フォルダと出力フォルダを設定(相対パス)
input_folder = "tsuchiya_normal"
output_folder = "tsuchiya_normal_with_noise"
os.makedirs(output_folder, exist_ok=True)
# SN比を計算する関数
def add_white_noise(audio, snr_db):
rms_signal = np.sqrt(np.mean(audio**2))
rms_noise = rms_signal / (10**(snr_db / 20))
noise = np.random.normal(0, rms_noise, audio.shape)
return audio + noise
# フォルダ内のwavファイルにホワイトノイズを追加
for file_name in os.listdir(input_folder):
if file_name.endswith(".wav"):
input_path = os.path.join(input_folder, file_name)
# 音声ファイルを読み込む
audio, samplerate = sf.read(input_path)
# ランダムなSN比(20~10dB)を生成(整数)
snr_db = random.randint(10, 20)
# ホワイトノイズを追加
noisy_audio = add_white_noise(audio, snr_db)
# 出力ファイル名にSN比を追加(整数値)
file_name_no_ext, ext = os.path.splitext(file_name)
output_file_name = f"{file_name_no_ext}_SNR{snr_db}dB{ext}"
output_path = os.path.join(output_folder, output_file_name)
# 出力フォルダに保存
sf.write(output_path, noisy_audio, samplerate)
print(f"Processed {file_name} with SNR {snr_db} dB")
プログラム実行すると、
同じ階層に「tsuchiya_normal_with_noise」というフォルダが作成されると思います。
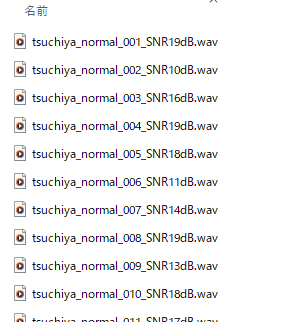
このフォルダには、「tsuchiya_normal」に保存されていたwavファイルに
SN比20~10dBのホワイトノイズがランダムで追加されています。
また、保存名に SN比が何dBのノイズが追加されたのかわかるようにしてあります。
ダウンロードした雑音を追加
ここでは、ダウンロードした「bgm」や「効果音」などを
メインの音声にのせるプログラムを考えていきます。
引き続きメインの音声に「tsuchiya_normal」を使用します。
のせる音が準備できていない方は、こちらの記事でおすすめのサイトを紹介していますので、
お好きなサイトからダウンロードしてみてください。
※「tsuchiya_normal」に保存されているwavファイルは100コなので、
100種類ダウンロードしてみてください。

この記事では、「VSQ plus+」というサイトから100種類ダウンロードしたものを使用します。
先ほどと同じ階層に「NOISE」というフォルダ名で保存しました。
「ノイズ追加」というフォルダに
こちらのプログラム「with_noise.py」という名前で保存してください。
プログラムを実行すると、同じ階層に
「WITH_NOISE」というフォルダが作成されます。
「with_noise.py」
import os
import random
import numpy as np
import soundfile as sf
from pydub import AudioSegment
# 入力フォルダと出力フォルダを設定(相対パス)
main_audio_folder = "tsuchiya_normal"
noise_folder = "NOISE"
output_folder = "WITH_NOISE"
os.makedirs(output_folder, exist_ok=True)
# SN比を計算してノイズを追加する関数
def add_noise_with_snr(main_audio, noise_audio, snr_db):
rms_main = np.sqrt(np.mean(main_audio**2))
rms_noise = np.sqrt(np.mean(noise_audio**2))
scaling_factor = rms_main / (10**(snr_db / 20)) / rms_noise
scaled_noise = noise_audio * scaling_factor
return main_audio + scaled_noise
# メイン音声フォルダ内のwavファイルを処理
for main_file in os.listdir(main_audio_folder):
if main_file.endswith(".wav"):
main_path = os.path.join(main_audio_folder, main_file)
main_audio, samplerate = sf.read(main_path)
# 雑音フォルダからランダムなノイズファイルを選択
noise_file = random.choice([f for f in os.listdir(noise_folder) if f.endswith(".mp3")])
noise_path = os.path.join(noise_folder, noise_file)
# ノイズを読み込み(mp3をwav形式に変換)
noise_audio = AudioSegment.from_mp3(noise_path)
noise_audio = np.array(noise_audio.get_array_of_samples()) / 2**15 # 正規化
# ノイズをメイン音声と同じ長さに調整(ループまたは切り詰め)
if len(noise_audio) < len(main_audio):
repeats = int(np.ceil(len(main_audio) / len(noise_audio)))
noise_audio = np.tile(noise_audio, repeats)[:len(main_audio)]
else:
noise_audio = noise_audio[:len(main_audio)]
# ランダムなSN比(20~10dB)を生成
snr_db = random.randint(10, 20)
# ノイズを追加
noisy_audio = add_noise_with_snr(main_audio, noise_audio, snr_db)
# 出力ファイル名にノイズ名とSN比を追加
main_name, main_ext = os.path.splitext(main_file)
noise_name, _ = os.path.splitext(noise_file)
output_file_name = f"{main_name}_with_{noise_name}_SNR{snr_db}dB{main_ext}"
output_path = os.path.join(output_folder, output_file_name)
# 出力フォルダに保存
sf.write(output_path, noisy_audio, samplerate)
print(f"Processed {main_file} with {noise_file} at SNR {snr_db} dB")
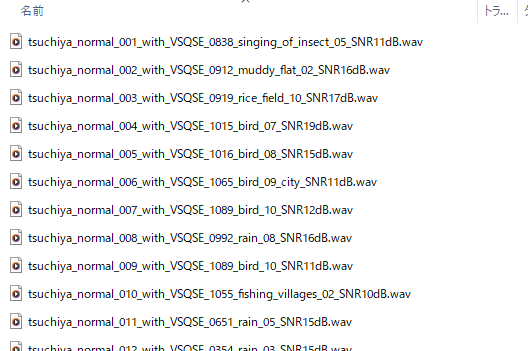
「WITH_NOISE」には
「メインの音声ファイル名」_with_「追加したファイル名」_「SN比」.wav
という順番の名前で保存されます。
先ほどと同様にSN比は10~20dBの間でランダムに追加されます。

コメント